Tư Duy Lớn Của Genomics Hiện Đại: Reference Genome Và Hệ Sinh Thái Đa Omics

Sinh học phân tử hiện đại được xây dựng trên một nguyên tắc nền tảng: mọi dạng thông tin sinh học — từ trình tự DNA đến gene expression (biểu hiện gene), từ cấu trúc nhiễm sắc thể đến trạng thái methyl hóa — đều có thể được quy về một hệ tọa độ dùng chung. Bài viết này lý giải tại sao nguyên tắc đó là xương sống của genomics hiện đại, và bằng cách nào hàng chục công nghệ tưởng chừng rời rạc lại kết hợp thành một kiến trúc nhận thức thống nhất.
1. Hệ Tọa Độ Genome
1.1. Reference Genome Là Gì?
Reference genome (reference genome) là một trình tự DNA hoàn chỉnh, được lắp ráp và chú thích công khai, dùng làm chuẩn để định vị và so sánh mọi dữ liệu genomics. Đối với người, phiên bản đang được sử dụng phổ biến nhất là GRCh38 (còn gọi là hg38), bao gồm khoảng 3,2 tỷ cặp base trải dài trên 23 cặp nhiễm sắc thể.
Trước khi Dự án Human Genome (Human Genome Project) hoàn thành vào năm 2003, mỗi phòng thí nghiệm nghiên cứu một đoạn DNA riêng lẻ mà không có cách nào biết đoạn đó nằm ở đâu trong toàn cảnh. Reference genome thay đổi điều đó bằng cách cung cấp một bản đồ toàn phần, tương tự như lần đầu tiên bản đồ thế giới được vẽ ra, cho phép mọi khám phá địa lý mới đều có thể được định vị chính xác trong không gian chung.
1.2. Vì Sao Cần Điểm Quy Chiếu Chung?
Giá trị của reference genome không nằm ở sự “hoàn hảo” hay tính “đại diện”; trên thực tế mỗi người mang khoảng 4–5 triệu vị trí khác biệt so với GRCh38. Giá trị của nó nằm ở chỗ nó là điểm quy chiếu trung lập và dùng chung: khi một nhà nghiên cứu ở Hà Nội và một nhà nghiên cứu ở Boston đều nói đến “vị trí 179,148,114 trên nhiễm sắc thể 17”, họ biết chính xác mình đang bàn về cùng một điểm trên human genome.
Không có hệ tọa độ này, dữ liệu từ các phòng thí nghiệm, công nghệ, và nghiên cứu khác nhau sẽ không thể đối chiếu hay tích hợp. Mỗi lớp thông tin omics đều được “neo” vào reference genome — đây chính là cơ chế cho phép multi-omics integration mà chúng ta sẽ xem xét ở phần sau.
1.3. Từ Reference Genome Đến Pangenome
GRCh38 vẫn còn một giới hạn quan trọng: nó đại diện cho một trình tự đơn duy nhất, không bao phủ được toàn bộ sự đa dạng di truyền của loài người. Năm 2022, nhóm nghiên cứu T2T (Telomere-to-Telomere) hoàn thành lần đầu tiên một bộ genome người thực sự không có khoảng trống, giải trình tự thành công cả các vùng cho tới nay vẫn bị bỏ trống trong GRCh38 như vùng centromere và các đoạn lặp satellite (Nurk et al., 2022).
Tiếp đó, khái niệm pangenome (pangenome: biểu diễn sự đa dạng di truyền của toàn bộ một loài dưới dạng đồ thị graph thay vì một trình tự đơn) xuất hiện để bổ sung cho reference genome truyền thống. Dự án Human Pangenome Reference Consortium công bố phiên bản đầu tiên năm 2023, tích hợp genome của 47 cá thể từ nhiều quần thể khác nhau trên thế giới, đánh dấu bước tiến quan trọng về độ bao phủ đa dạng di truyền (Liao et al., 2023).
2. Hệ Sinh Thái Công Nghệ Omics
2.1. Câu Hỏi Quyết Định Công Nghệ
Reference genome chỉ là bản đồ tĩnh; nó không thể tự cho ta biết điều gì đang xảy ra trong một tế bào bệnh, một mô đang phát triển, hay một cá thể mang biến thể di truyền hiếm. Để rút ra tri thức sinh học, cần phải đo lường, và mỗi loại câu hỏi sinh học đòi hỏi một loại phép đo khác nhau.
Đây là lý do genomics hiện đại không phải là một công nghệ mà là một hệ sinh thái công nghệ (technology ecosystem: tập hợp các công nghệ bổ sung cho nhau để giải quyết các câu hỏi sinh học ở nhiều chiều thông tin). Hãy hình dung một thành phố: bản đồ đường phố (reference genome) là cơ sở không thể thiếu, nhưng để hiểu cuộc sống đô thị, ta cần thêm dữ liệu giao thông, thống kê dân số, bản đồ địa chất, và cơ sở hạ tầng kỹ thuật, mỗi loại trả lời một loại câu hỏi khác nhau về cùng một thực thể.
2.2. Bản Đồ Các Lớp Omics
Mỗi câu hỏi sinh học căn bản ánh xạ vào một lớp dữ liệu omics cụ thể. Bảng 2.1 tóm tắt những lớp chính đang được sử dụng rộng rãi.
| Câu hỏi sinh học | Lớp thông tin | Lĩnh vực |
|---|---|---|
| DNA cá thể này khác gì với tham chiếu? | Biến thể di truyền | Genomics |
| Gene nào đang được biểu hiện, ở mức độ nào? | Lượng RNA | Transcriptomics |
| Vùng DNA nào đang “mở” hay “đóng”? | Trạng thái chromatin | Epigenomics |
| Protein nào hiện diện và ở nồng độ bao nhiêu? | Lượng protein | Proteomics |
| Phân tử nhỏ nào đang lưu thông trong tế bào? | Chất chuyển hóa | Metabolomics |
| DNA gấp lại trong không gian như thế nào? | Cấu trúc 3D nhiễm sắc thể | 3D Genomics |
Bảng 2.1. Ánh xạ từ câu hỏi sinh học đến lớp thông tin omics tương ứng.
3. Hai Thế Hệ Giải Trình Tự
Để thu thập dữ liệu cho hầu hết các lớp omics, bước đầu tiên là chuyển phân tử sinh học thành dữ liệu số thông qua sequencing (giải trình tự: quá trình xác định thứ tự các nucleotide trong một phân tử DNA hoặc RNA). Hai thế hệ công nghệ hiện đang tồn tại song song với những triết lý khác nhau về cách đọc thông tin.
3.1. Short-read Sequencing
Short-read sequencing (giải trình tự đọc ngắn), tiêu biểu là nền tảng Illumina, đọc các đoạn DNA dài 100–300 nucleotide nhưng với số lượng cực lớn, lên đến hàng trăm triệu đoạn mỗi lần chạy. Triết lý cốt lõi là sequencing depth (độ sâu đọc: số lần trung bình mỗi vị trí trên genome được đọc) bù cho độ dài: mỗi đoạn ngắn, nhưng khi hàng triệu đoạn chồng lấp tại cùng một vị trí, trình tự được xác định với độ chính xác lên đến 99,9%.
Điểm mạnh là chi phí thấp và thông lượng cao. Điểm yếu là đoạn ngắn không thể vượt qua các vùng DNA lặp dài, tương tự như cố ghép một bức tranh jigsaw khi mọi mảnh đều trông giống hệt nhau.
3.2. Long-read Sequencing
Long-read sequencing (giải trình tự đọc dài), gồm PacBio HiFi và Oxford Nanopore, đọc ít đoạn hơn nhưng mỗi đoạn dài hàng chục đến hàng trăm nghìn nucleotide. Triết lý ở đây là đọc liên tục theo ngữ cảnh: giống như đọc cả một chương sách thay vì nhận hàng nghìn mảnh vụn từ các trang khác nhau.
Oxford Nanopore có thêm khả năng đặc biệt: đọc trực tiếp tín hiệu điện hóa khi phân tử DNA đi qua nanopore, cho phép phát hiện methylation (methyl hóa: quá trình gắn nhóm methyl lên cytosine, một dạng biến đổi epigenetic điều hòa gene expression) ngay trong quá trình giải trình tự mà không cần thí nghiệm riêng biệt.
3.3. So Sánh Và Tính Bổ Sung
Hai thế hệ không cạnh tranh mà bổ trợ nhau. Long-read cung cấp cấu trúc khung, phân giải vùng lặp và xác định structural variant (biến thể cấu trúc: các biến đổi DNA lớn như mất đoạn, nhân đoạn, hoặc đảo đoạn nhiễm sắc thể). Short-read cung cấp độ chính xác nucleotide trên toàn bộ genome với chi phí thấp hơn nhiều. Nhiều nghiên cứu quy mô lớn ngày nay kết hợp cả hai để đạt được genome assembly (lắp ghép genome) hoàn chỉnh nhất — đây chính là chiến lược giúp nhóm T2T hoàn thành trình tự đầy đủ đầu tiên.
4. Các Lớp Omics Chính
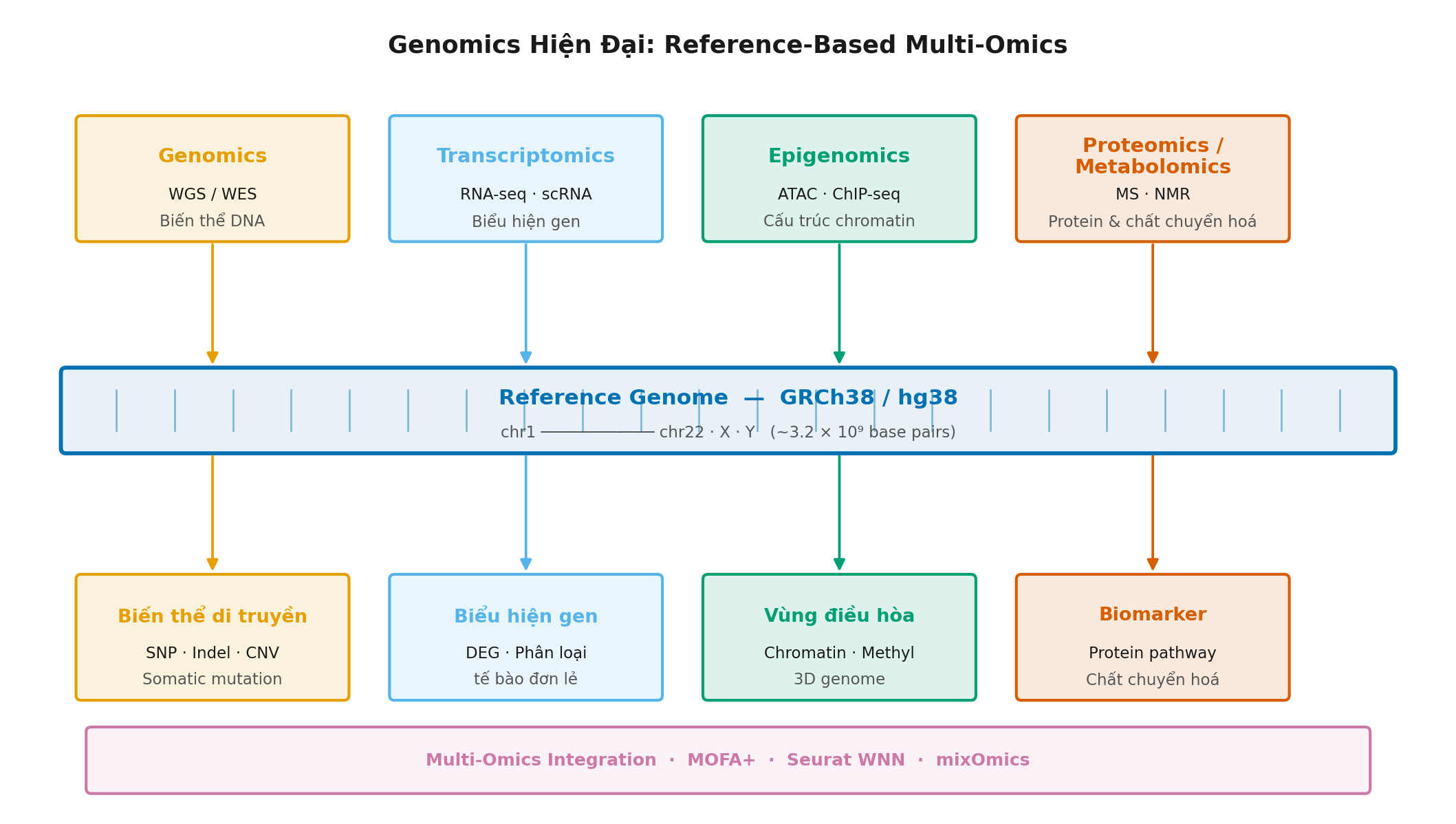
Mỗi lớp omics là một chiều thông tin khác nhau về cùng một thực thể sinh học. Tất cả đều được định vị trên hệ tọa độ chung của reference genome, đây chính là điều cho phép tích hợp chúng lại.
Hình 4.1. Reference genome đóng vai trò hệ trục tọa độ trung tâm, nơi mọi lớp thông tin omics đều được neo vào cùng một không gian tọa độ.
4.1. Genomics
Genomics nghiên cứu toàn bộ trình tự DNA của một sinh vật và các biến thể so với tham chiếu. Mỗi cá thể người mang khoảng 4–5 triệu SNP (single nucleotide polymorphism: đa hình đơn nucleotide, tức là vị trí một cặp base được thay thế bởi cặp base khác), cùng hàng nghìn biến thể cấu trúc lớn hơn.
Trong bối cảnh bệnh lý, genomics so sánh genome (genome: toàn bộ vật liệu di truyền của một sinh vật) của tế bào bệnh với tế bào lành từ cùng một cá thể để tìm đột biến somatic (somatic mutation: biến đổi DNA chỉ xuất hiện ở tế bào sinh dưỡng, không có trong tế bào mầm và không di truyền cho thế hệ sau). Đây là bước khởi đầu của y học chính xác trong ung thư học.
4.2. Transcriptomics
Nếu genomics đọc “bản thảo” DNA, transcriptomics lắng nghe “những gì đang được đọc to”. Genome mang toàn bộ thông tin di truyền, nhưng trong mỗi loại tế bào và tại mỗi thời điểm, chỉ một phần nhỏ các gene được phiên mã (transcription: quá trình tổng hợp RNA từ khuôn mẫu DNA). Đây là cơ sở của tính đặc hiệu tế bào: tế bào cơ tim và tế bào thần kinh mang cùng bộ DNA nhưng biểu hiện những tập gene hoàn toàn khác nhau.
RNA-seq đo lường lượng RNA từ mỗi gene, tạo ra ảnh chụp nhanh về trạng thái gene expression toàn bộ genome tại một thời điểm. Single-cell RNA-seq (scRNA-seq) tiến thêm một bước: thay vì lấy trung bình tín hiệu của hàng triệu tế bào, nó đọc gene expression profile của từng tế bào riêng lẻ. Điều này cho phép nhận diện tiểu quần thể tế bào (cell subpopulation) ẩn bên trong một mô, phân tích quỹ đạo biệt hóa, và xác định tế bào nào trong khối u đang kháng thuốc.
4.3. Epigenomics
DNA trong tế bào không tồn tại ở trạng thái “trần”. Nó cuộn chặt quanh các protein histone (histon: protein tạo nên cấu trúc cuộn DNA trong nhân tế bào), tạo thành chromatin (chất nhiễm sắc: phức hợp DNA và protein trong nhân). Trạng thái của chromatin — bao gồm vùng nào đang mở, vùng nào đang đóng và các histone được đánh dấu hóa học như thế nào — quyết định gene nào được phép phiên mã.
Đây là lĩnh vực epigenomics: nghiên cứu các tầng điều hòa nằm trên trình tự DNA mà không thay đổi trình tự đó. ATAC-seq xác định vùng chromatin đang mở (tức là đang hoạt động điều hòa), ChIP-seq (chromatin immunoprecipitation sequencing) tìm vị trí các protein điều hòa gắn vào DNA, và WGBS (whole-genome bisulfite sequencing) đo mức độ methyl hóa trên từng cytosine toàn bộ genome. Tất cả tín hiệu này đều được ánh xạ về cùng một tọa độ trên reference genome.
Điều đặc biệt quan trọng về epigenomics là epigenome có thể thay đổi theo môi trường, tuổi tác, và bệnh lý, trong khi genome chỉ thay đổi bởi đột biến. Đây là cơ sở khoa học cho các nghiên cứu về tác động của lối sống và môi trường lên nguy cơ bệnh tật.
4.4. Cấu Trúc Không Gian Genome
Genome không phải là một sợi chỉ thẳng. Trong nhân tế bào, DNA gấp khúc theo kiến trúc ba chiều được bảo tồn chặt chẽ. Hai vùng DNA cách xa nhau hàng triệu base pair (cặp base: đơn vị đo độ dài DNA, một bp tương đương một cặp nucleotide bổ sung) trên trình tự tuyến tính có thể đứng sát nhau trong không gian và tương tác trực tiếp để điều hòa gene expression của nhau.
Hi-C là công nghệ chụp ảnh toàn bộ các tương tác không gian trong nhân: DNA đang tiếp xúc vật lý được cố định, cắt, và giải trình tự cùng nhau, tạo ra ma trận tương tác toàn bộ genome. Hiểu cấu trúc này lý giải tại sao nhiều biến thể di truyền liên quan đến bệnh (GWAS variants) nằm xa target gene hàng megabase trên trình tự, nhưng vẫn điều hòa gene expression đó thông qua tiếp xúc không gian.
5. Tích Hợp Đa Omics
5.1. Logic Của Tích Hợp
Không có lớp omics nào, nếu đứng một mình, có thể trả lời đầy đủ một câu hỏi sinh học phức tạp. Sức mạnh thực sự nằm ở multi-omics integration (tích hợp đa omics: kết hợp phân tích đồng thời nhiều lớp omics từ cùng một hệ sinh học): kết hợp nhiều lớp trong cùng một hệ tọa độ để có cái nhìn đa chiều về cùng một hiện tượng sinh học.
Việc tích hợp này khả thi vì tất cả các lớp omics đều sử dụng reference genome làm điểm quy chiếu chung. Một tín hiệu epigenomic tại vị trí X trên nhiễm sắc thể 17 có thể được đối chiếu ngay lập tức với biến thể genomic tại cùng vị trí, và với mức gene expression của gene lân cận, vì tất cả chia sẻ cùng một hệ tọa độ.
5.2. Ví Dụ Ứng Dụng Lâm Sàng
Xét bài toán nghiên cứu cơ chế kháng thuốc trong ung thư vú. Genomics phát hiện đột biến trong gene PIK3CA, nhưng đột biến này xuất hiện ở cả tế bào nhạy thuốc lẫn kháng thuốc, chưa đủ để giải thích cơ chế. Transcriptomics cho thấy con đường tín hiệu PI3K/AKT bị kích hoạt mạnh hơn ở nhóm kháng thuốc, nhưng tại sao? ATAC-seq tiết lộ một enhancer (vùng tăng cường: trình tự DNA không mã hóa protein nhưng điều hòa tăng cường gene expression ở khoảng cách xa) lân cận resistance gene đang mở ra. ChIP-seq xác nhận một transcription factor đang gắn vào vùng đó. Cuối cùng, scRNA-seq phát hiện chỉ khoảng 5% tế bào trong khối u — một tiểu quần thể ẩn — mang toàn bộ đặc điểm kháng thuốc.
Mỗi lớp thông tin đơn lẻ chỉ cung cấp một mảnh ghép. Chính khả năng chồng lấp tất cả chúng trên một hệ tọa độ reference genome mới tạo ra bức tranh đầy đủ và có giá trị lâm sàng.
6. Tư Duy Từ Câu Hỏi Sinh Học
Một sai lầm phổ biến khi mới tiếp cận tin sinh học là tư duy bắt đầu từ công nghệ: “Tôi có dữ liệu RNA-seq, tôi nên làm gì với nó?” Chuỗi tư duy đúng đắn ngược lại: bắt đầu từ câu hỏi sinh học cụ thể, suy ra loại dữ liệu phù hợp, rồi mới chọn công nghệ và phương pháp phân tích.
Câu hỏi sinh học xác định lớp thông tin omics phù hợp, lớp thông tin đó xác định công nghệ thu thập, và công nghệ xác định phương pháp phân tích.
Reference genome là nền tảng bất biến xuyên suốt toàn bộ chuỗi này. Dù câu hỏi liên quan đến human genome, chuột, lúa hay vi khuẩn đường ruột, nguyên tắc đều như nhau: xây dựng (hoặc sử dụng) bản đồ tham chiếu, rồi đo lường mọi thứ tương đối so với bản đồ đó. Sự nhất quán này là lý do tại sao kiến trúc tư duy của genomics có thể được áp dụng rộng rãi cho mọi sinh vật và mọi câu hỏi sinh học.
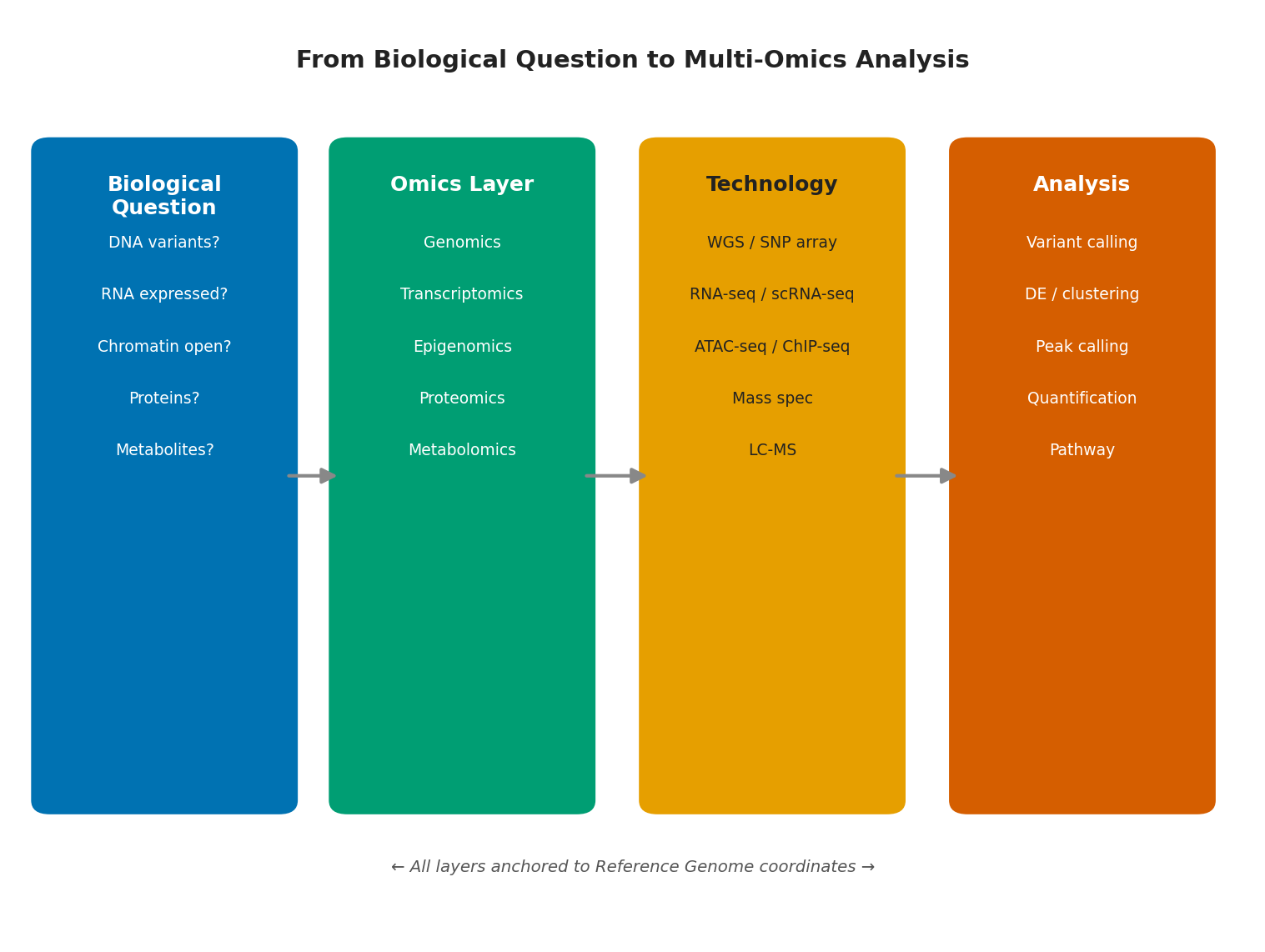 Hình 6.1. Luồng tư duy đúng đắn trong genomics: bắt đầu từ câu hỏi sinh học, suy ra lớp omics phù hợp, rồi mới chọn công nghệ và phương pháp phân tích.
Hình 6.1. Luồng tư duy đúng đắn trong genomics: bắt đầu từ câu hỏi sinh học, suy ra lớp omics phù hợp, rồi mới chọn công nghệ và phương pháp phân tích.
Kết Luận
Reference genome không chỉ là một trình tự DNA; đó là ngôn ngữ chung của sinh học phân tử hiện đại. Mọi lớp omics đều mượn hệ tọa độ của nó để “nói chuyện” với nhau. Mỗi công nghệ — từ short-read sequencing đến Hi-C, từ ATAC-seq đến scRNA-seq — là một cách khác nhau để quan sát cùng một thực thể sinh học. Và chính khả năng tích hợp tất cả những quan sát đó trên một nền tảng chung mới tạo ra sức mạnh thực sự của genomics hiện đại: đi từ câu hỏi sinh học đến tri thức cơ học chính xác.
Khái niệm pangenome và T2T genome đang mở rộng nền tảng đó thêm một bước, cho phép nghiên cứu sự đa dạng di truyền ở cấp độ toàn loài thay vì chỉ một cá thể. Đây là hướng phát triển tất yếu của genomics trong thập kỷ tới.
Trong các bài tiếp theo, mỗi lớp omics sẽ được phân tích chuyên sâu về cơ sở lý thuyết và thiết kế thí nghiệm: RNA-seq và scRNA-seq, ATAC-seq và epigenomics, Hi-C và cấu trúc không gian genome. Các bài hướng dẫn thực hành (tutorial) song song sẽ giúp bạn áp dụng những khái niệm này vào phân tích dữ liệu thực tế.
Tài Liệu Tham Khảo
Claussnitzer, M., Cho, J. H., Collins, R., Cox, N. J., Dermitzakis, E. T., Hurles, M. E., … McCarthy, M. I. (2020). A brief history of human disease genetics. Nature, 577(7789), 179–189. https://doi.org/10.1038/s41586-019-1879-7
Nurk, S., Koren, S., Rhie, A., Rautiainen, M., Bzikadze, A. V., Mikheenko, A., … Phillippy, A. M. (2022). The complete sequence of a human genome. Science, 376(6588), 44–53. https://doi.org/10.1126/science.abj6987
Stark, R., Grzelak, M., & Hadfield, J. (2019). RNA sequencing: The teenage years. Nature Reviews Genetics, 20(11), 631–656. https://doi.org/10.1038/s41576-019-0150-2
Buenrostro, J. D., Wu, B., Chang, H. Y., & Greenleaf, W. J. (2015). ATAC-seq: A method for assaying chromatin accessibility genome-wide. Current Protocols in Molecular Biology, 109(1), 21.29.1–21.29.9. https://doi.org/10.1002/0471142727.mb2129s109
Lieberman-Aiden, E., van Berkum, N. L., Williams, L., Imakaev, M., Ragoczy, T., Telling, A., … Dekker, J. (2009). Comprehensive mapping of long-range interactions reveals folding principles of the human genome. Science, 326(5950), 289–293. https://doi.org/10.1126/science.1181369
Liao, W. W., Asri, M., Ebler, J., Doerr, D., Haukness, M., Hickey, G., … Paten, B. (2023). A draft human pangenome reference. Nature, 617(7960), 312–324. https://doi.org/10.1038/s41586-023-05896-x
ENCODE Project Consortium. (2012). An integrated encyclopedia of DNA elements in the human genome. Nature, 489(7414), 57–74. https://doi.org/10.1038/nature11247
Explore more like this
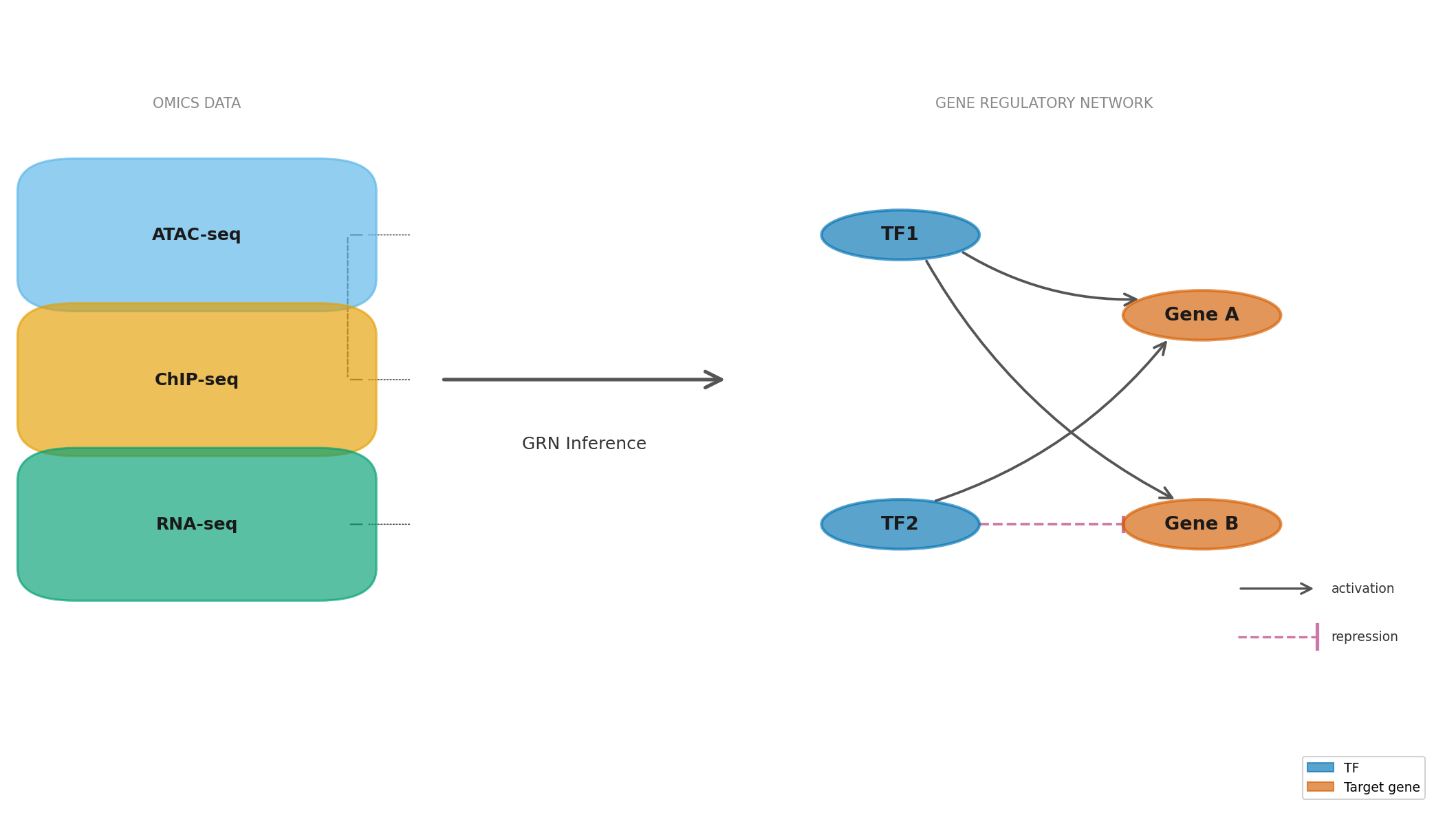
Gene Regulatory Network: Từ Phân Tử Đến Multi-Omics Và Ứng Dụng Lâm Sàng
Genome của người chứa khoảng 20.000 gene mã hóa protein, nhưng không phải gene nào cũng hoạt động ở mọi tế bào trong mọi thời điểm. Một tế bào gan,...
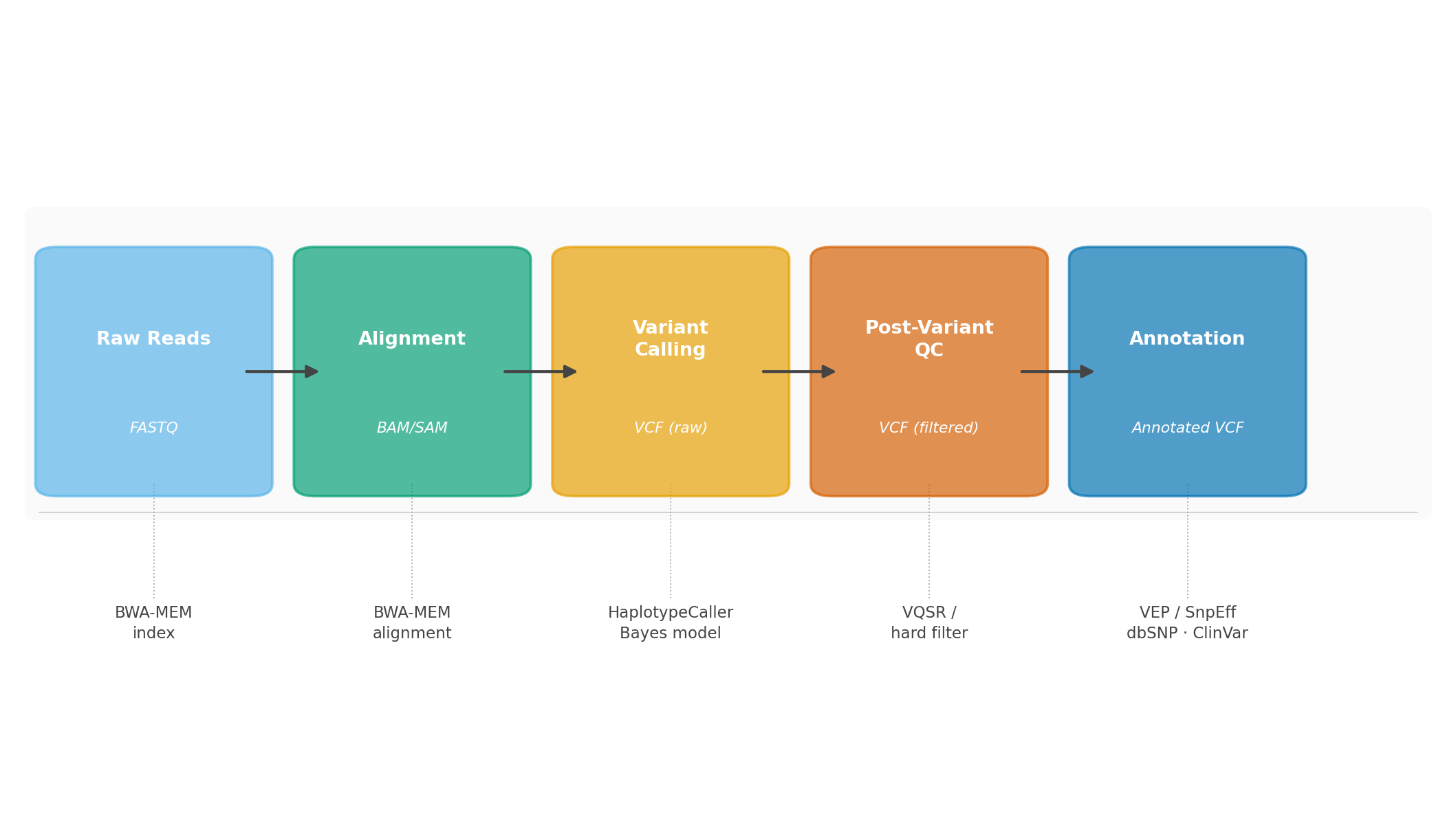
Từ Dữ Liệu Thô Đến Biến Thể Di Truyền: Genome Alignment, Variant Calling, QC và Annotation
Khi một mẫu DNA được đưa vào máy giải trình tự, kết quả trả về không phải là một câu trả lời hoàn chỉnh về bộ genome của cá thể...
Transcriptomics: Hành Trình Giải Mã Hệ Phiên Mã và Các Công Nghệ Chủ Chốt
Tế bào người chứa khoảng 3,2 tỷ cặp bazơ DNA — nhưng không phải tất cả đều được “đọc” cùng một lúc, hay ở mọi loại tế bào. Một tế...
Comments